稻米就算採收,也無法直接食用,需要經過一系列的加工才能送到消費者的手裡。
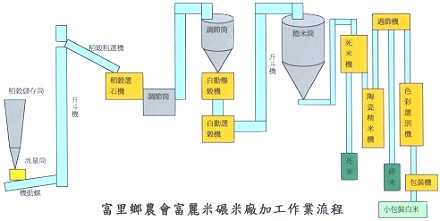
(圖片來源:富里鄉農會)
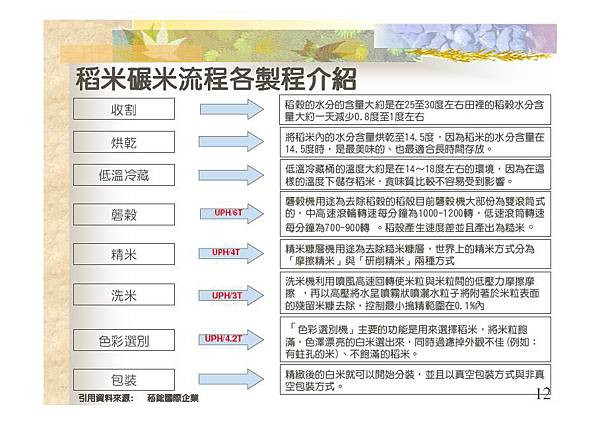
這個流程跟加工資料的流程並沒有什麼太大的差異,常見的資料基礎加工流程包括
當資料產生後,我們通常不會在資料產生的地方處理資料,而是會透過資料採集的方式將資料「推」到另外一個地方來做處理。例如使用者在手機 App 上留下的互動資料後,手機會將資料透過 RESTFul API 推送到後端伺服器,這就是資料採集的最基本的方法。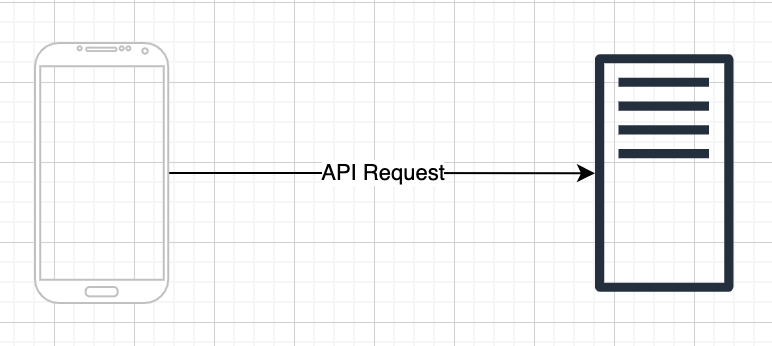
如果只有一個使用者,當然可以用這種簡單的方式來處理。但隨著資料量越大,例如到了百萬等級的使用者時,單一台機器通常無法應付如此龐大的資料量,因此採集的方式也需要加以改變才能應付。像下圖就是應用 Apache Kafka 這種分散式的技術來搜集資料。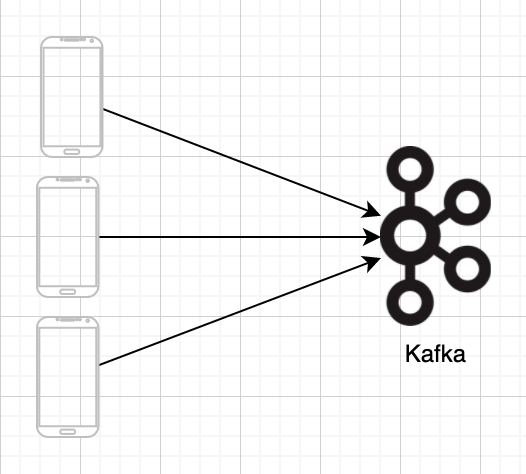
除了像上述由資料源主動推資料出去的方式外,還有一種採集是使用「拉」的模式。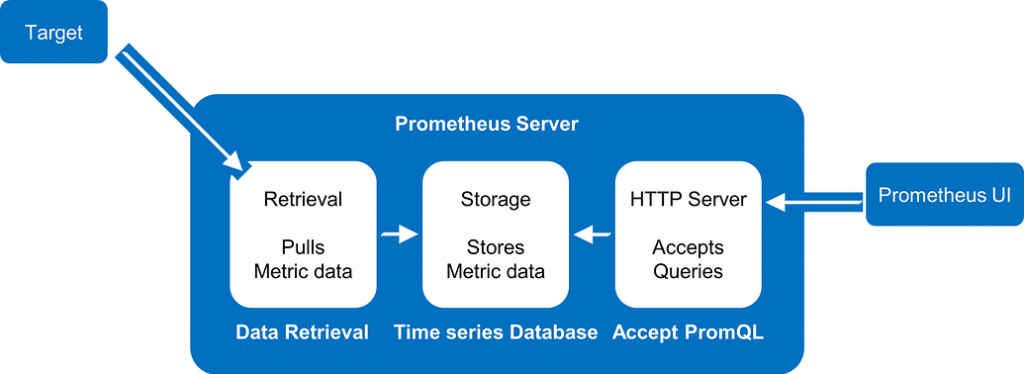
(https://community.xvigil.com/t/how-to-use-prometheus-to-monitor-complex-applications-and-infrastructure/1813)
普羅米修斯是一種搜集機器資料的工具。需要搜集資料的機器可以安裝普羅米修斯的 Exporter,這可以視為是機器資料的對外接口,普羅米修斯會定期地透過這個街口去拉資料並儲存下來,方便後續的追蹤以及分析。
雖然說是「大數據」,但也不是所有資料都值得搜集。實務上有很多「壞資料」或「不乾淨」的資料產生,如果放任這些品質不良的資料進入資料庫只會影響到資料品質,因此通常我們在接收原始資料時會有個基本的驗證條件,像是:
來源驗證
由於要接收資料,所以收集資料的伺服器通常會對外部開放,這時候非常有可能被除了合法對象的其他對象(像是爬蟲或是惡意攻擊)亂打,如果沒有做基本的身份驗證,可能會收到非常多沒有用的訊息甚至把伺服器打掛。
欄位驗證
通常我們在搜集資料時會先訂好要溝通的規格(Spec),以方便後續的分析與處理。實務上有時候會因為終端 App 版本不同或是開發時手滑打錯造成 Spec 不一至的情況,因此需要基本的欄位驗證。
格式驗證
不同屬性的資料通常有其合法的資料格式,例如身高就是數值資料、Email 是字串資料而且需要服合特定的模式,當這些資料格式不對時,會直接影響後續的處理,這時候我們也會考慮在收資料時就直接去判斷資料格式是否合法。
雖然說我們不需要壞資料進入後續的處理,但是壞資料本身也是有其分析價值,像是分析到底是誰亂傳資料,或是前端再送資料時有沒有發生問題。所以有些情況不會將所有驗證失敗的資料丟棄,而是會導入另外一個資料儲存地以供後續的分析與觀察。
當資料通過基本驗證後,在正式使用之前,還是需要清洗一番。資料清洗的功夫非常多元和複雜,這邊只能介紹幾個比較常遇到的情境。
(Multi-parser architecture for query processing. 2001)
多久已內相同的才叫重複值?一個小時、一天、還是一個月?
重複到什麼樣子才叫重複?如果事件內容一模一樣僅有發生時間不同那算是重複值嗎?
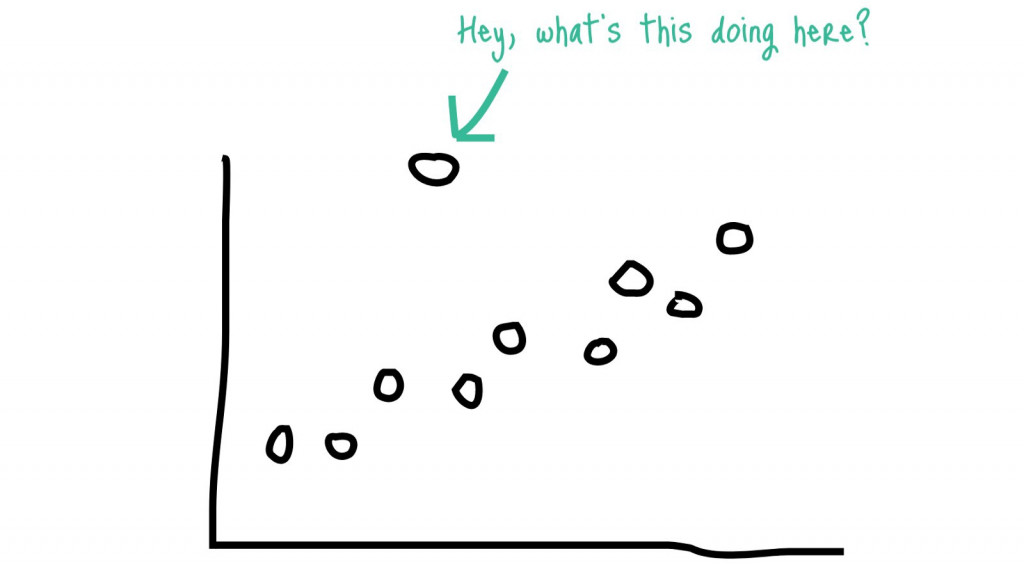
(https://medium.com/@praveengovi.analytics/outliers-what-it-say-during-data-analysis-75d664dcce04)
上述這些程序看似繁瑣以及無趣,但還是回到這句老話**「Garbage in, garbage out」**,資料在採集後還是需要驗證以及清洗來確保資料品質,任何處理資料的人都不可對這個過程馬乎行事。

